
diff options
| author | Pinapelz <yukais@pinapelz.com> | 2024-08-19 19:02:54 -0700 |
|---|---|---|
| committer | Pinapelz <yukais@pinapelz.com> | 2024-08-19 19:02:54 -0700 |
| commit | d9a21b249b864b1ca46b514e79d0f9e855bab45a (patch) | |
| tree | 0c369645ebd80eb9b8febd47626edeac2734440f | |
| parent | 941c088466f16ec59eaaed0fa6892d36f481ea07 (diff) | |
complete mojibake post
| -rw-r--r-- | src/content/blog/mojibake.md | 103 |
1 files changed, 89 insertions, 14 deletions
diff --git a/src/content/blog/mojibake.md b/src/content/blog/mojibake.md index 92ac106..d57f2f9 100644 --- a/src/content/blog/mojibake.md +++ b/src/content/blog/mojibake.md @@ -1,34 +1,109 @@ --- -title: 'Japanese Mojibake - L�ss �f D�t�' -description: 'Some encoding errors can result in loss of data' -pubDate: 'May 6 2024' +title: 'Mojibake. What is it?' +description: 'The cryptic text you see as a result of encoding/decoding' +pubDate: 'Aug 19 2024' --- -For the uninitiated, "mojibake" is the garbled text you see as a result of *encoding errors*. In the age of digital communication, bytes are sent across the globe in the blink of an eye. Different encoding and decoding schemes are used to interpret these bytes into human-readable text. +Ever see a bunch of garbled text on a website or in a program? Perhaps what you're seeing is mojibake. -Below is an example of the word "Hello World" encoded in UTF-8 and then decoded in hexadecimal form: +For the uninitiated, mojibake is the garbled text you see as a result of decoding bytes that have been encoded with a different standard. This usually results in garbled text that is unreadable or nonsensical. + + +<div align="center"> +<img src="https://files.catbox.moe/ja7vzo.png"/> +<p>AI The Sommnium Files: Nirvana Initiative, example of mojibake used in game</p> +</div> + +--- + +For any text to reach your computer screen, it must first be converted from a stream of bytes to a human-readable format. + +In other words, for person A to send a message to person B, the message must be encoded by person A and then decoded by person B. + +As an example, let's encode "你好" (Hello in Simplified Chinese) into bytes using the UTF-8 encoding scheme. The result would be the following sequence of bytes (shown as HEX): ``` -\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64 +E4 BD A0 E5 A5 BD ``` +Then this sequence of bytes can be sent over the internet or stored in a file. + +Now if you were to interpret these bytes as UTF-8 again when decoding, you would get the original text "你好". -When data is encoded using one scheme and decoded using another, the result is often mojibake (especially when it comes to non-ASCII characters). +But what if you were to interpret these bytes using a different standard like big5? The result would be: +``` +ァAヲn +``` -Different schemes were developed in the first place to accommodate different languages and scripts. ASCII, for example, is a 7-bit encoding scheme that can represent 128 characters. This was fine for English, but not so much for other languages. +It becomes a garbled mess that is far from the original text. This is mojibake. + +In the early days of computing, Different encoding schemes were developed in the first place to accommodate different languages, since obviously, not all languages can be represented with the same number of characters. These days we have more universal encoding schemes like UTF-8, which can represent every character in the Unicode standard. +--- + # The Problem There are still many legacy programs and systems that use older encoding schemes. When data is passed between systems that use different encoding schemes, the result can be mojibake. -If you have a sequence of bytes that were encoded using one scheme and then try to decode it assuming its another scheme, you'll get mojibake. +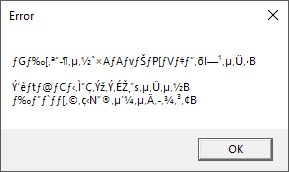 + +In the world of UTF-8, this means that the bytes are interpreted as a different character than intended. This can result in text that is unreadable or nonsensical. + +This can actually mean data loss in some cases where the mismatched decoding format doesn't have enough characters to represent the bytes uniquely. + +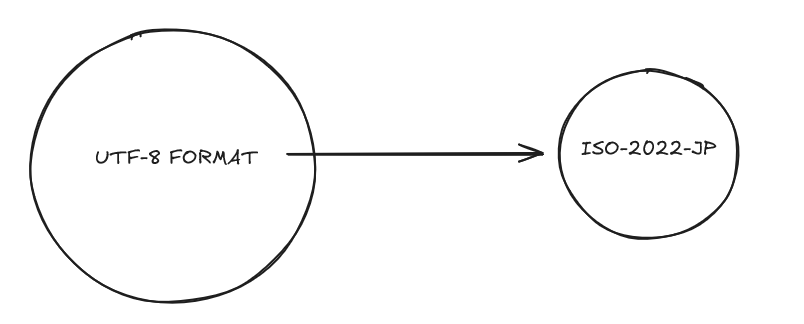 + +Not all UTF-8 characters can be represented in ISO-2022-JP, so what normally ends up happening is that the character is replaced with a placeholder character such as `�` (NULL) + +It would probably be fine if only 1 character was unreadable, but if a lot of characters are mapped to this placeholder, it can become impossible to recover the data from the mojibake since its original form has already been lost. + +Example: +``` +�乗而�����с�������������障�������� +���潟�潟�若����┃絎���������������絖��������с�障���� +�延根�帥���若�������333m�с���� +``` + +## Recovery +But let's say that we luck out and see that most of the characters in the mojibake have some form of representation after decoding. We can actually still recover the original text. + +I'll use another example from AI The Sommnium Files since I like the game so much. + +``` +迥ッ莠コ繧偵が繧ゅ>蜃コ縺輔○繝ュ +``` + +We need to come up with what encoding scheme was used to initially encode the text and then what decoding scheme was used to interpret the bytes. -*Examples from [A Field Guide to Japanese Mojibake](https://www.dampfkraft.com/mojibake-field-guide.html])* +Often times this is a guessing game, with more experience you can make better guesses based on what mojibake characters you're seeing. +Remember that only a subset of combinations of encoding/decoding schemes will result in readable text, so you can always assume that the format used to decode must have just as many if not more characters than the original encoding. -Let's take the following sentence as an example +In this case, the text was encoded with Shift-JIS and then decoded with UTF-8. All that's left to do is to reverse the steps. ->東京タワーの高さは333mです。 +1. Encode the text with Shift-JIS + +```python +text = "迥ッ莠コ繧偵が繧ゅ>蜃コ縺輔○繝ュ" +shift_jis_bytes = text.encode("shift_jis") +hex_representation = shift_jis_bytes.hex() +``` + +``` +E7 8A AF E4 BA BA E3 82 92 E3 82 AA E3 82 82 E3 81 84 E5 87 BA E3 81 95 E3 81 9B E3 83 AD +``` + +2. Decode the bytes with UTF-8 + +```python +hex_data = "E7 8A AF E4 BA BA E3 82 92 E3 82 AA E3 82 82 E3 81 84 E5 87 BA E3 81 9B E3 83 AD" +decoded_text = bytes.fromhex(hex_data.replace(" ", "")).decode('utf-8') +``` + +``` +犯人をオもい出せロ +``` +Now we can see that the original text was "犯人を思い出せロ" (which roughly translates to "Make them remember the culprit") -A larger problem arises when you try to convert mojibake back to its original form. Sometimes the original data is lost in the process of encoding and decoding. This is especially true when the original encoding scheme doesn't have a one-to-one/injective mapping with the target scheme. +I made a quick tool for scenarios like this where you don't know what encoding/decoding scheme was used. It'll try some of the most common combinations and show you the results. -And in some cases if the sequence of bytes aren't actually valid in the target encoding, it will usually get replaced with the NULL character (�) making that data lost for good. +You can find it [here](https://mojibaka.pinapelz.com/) |